
Page 42 - 江西普通高校专升本信息技术
P. 42
江西普通高校专升本信息技术
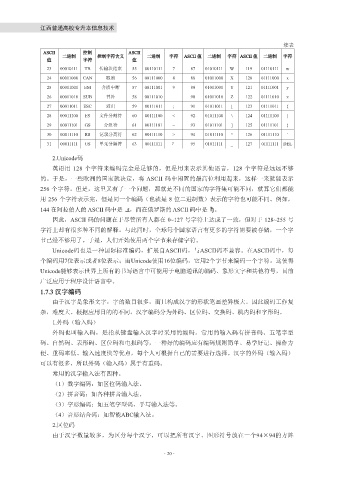
续表
ASCII 控制 ASCII
二进制 控制字符含义 二进制 字符 ASCII 值 二进制 字符 ASCII 值 二进制 字符
值 字符 值
23 00010111 TB 传输块结束 55 00110111 7 87 01010111 W 119 01110111 w
24 00011000 CAN 取消 56 00111000 8 88 01011000 X 120 01111000 x
25 00011001 EM 介质中断 57 00111001 9 89 01011001 Y 121 01111001 y
26 00011010 SUB 替补 58 00111010 90 01011010 Z 122 01111010 z
27 00011011 ESC 溢出 59 00111011 ; 91 01011011 [ 123 01111011 {
28 00011100 FS 文件分割符 60 00111100 < 92 01011100 \ 124 01111100 |
29 00011101 GS 分组符 61 00111101 = 93 01011101 ] 125 01111101 }
30 00011110 RS 记录分离符 62 00111110 > 94 01011110 ^ 126 01111110 `
31 00011111 US 单元分隔符 63 00111111 ? 95 01011111 _ 127 01111111 DEL
2.Unicode码
英语用 128 个字符来编码完全是足够的,但是用来表示其他语言,128 个字符是远远不够
的。于是,一些欧洲的国家就决定,将 ASCII 码中闲置的最高位利用起来,这样一来就能表示
256 个字符。但是,这里又有了一个问题,那就是不同的国家的字符集可能不同,就算它们都能
用 256 个字符表示完,但是同一个编码(也就是 8 位二进制数)表示的字符也可能不同。例如,
144 在阿拉伯人的 ASCII 码中是 ,而在俄罗斯的 ASCII 码中是 。
因此,ASCII 码的问题在于尽管所有人都在 0~127 号字符上达成了一致,但对于 128~255 号
字符上却有很多种不同的解释。与此同时,全球每个国家语言有更多的字符需要被存储,一个字
节已经不够用了。于是,人们开始使用两个字节来存储字符。
Unicode码也是一种国际标准编码,扩展自ASCII码,与ASCII码不兼容。在ASCII码中,每
个编码用7位表示或者8位表示;而Unicode使用16位编码,它用2个字节来编码一个字符。这使得
Unicode能够表示世界上所有的书写语言中可能用于电脑通讯的编码、象形文字和其他符号,目前
广泛应用于程序设计语言中。
1.7.3 汉字编码
由于汉字是象形文字,字的数目很多,而且构成汉字的形状笔画差异极大。因此编码工作复
杂,难度大。根据应用目的的不同,汉字编码分为外码、区位码、交换码、机内码和字形码。
1.外码(输入码)
外码也叫输入码,是指从键盘输入汉字时采用的编码。常用的输入码有拼音码、五笔字型
码、自然码、表形码、区位码和电报码等,一种好的编码应有编码规则简单、易学好记、操作方
便、重码率低、输入速度快等优点,每个人可根据自己的需要进行选择。汉字的外码(输入码)
可以有很多,所以外码(输入码)属于有重码。
常用的汉字输入法有四种。
(1)数字编码:如区位码输入法。
(2)拼音码:如各种拼音输入法。
(3)字形编码:如五笔字型码、手写输入法等。
(4)音形结合码:如智能ABC输入法。
2.区位码
由于汉字数量较多,为区分每个汉字,可以把所有汉字、图形符号放在一个94×94的方阵
·20·